How do I get the latest free Microsoft DP-100 exam practice questions?
Latest DP-100 exam dump, DP-100 pdf, online Microsoft DP-100 practice test questions free to improve skills and experience,
98.5% of exam pass rate selection lead4Pass DP-100 dumps: https://www.leadpass.com/dp-100.html (latest update)
Microsoft DP-100 exam pdf free download
[PDF Q1-Q13] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1ivuMI2KAwmZmsPjmEiO0TXsfU77hI1Km
Exam DP-100: Designing and Implementing a Data Science Solution on Azure: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-100
The Azure Data Scientist applies their knowledge of data science and machine learning to implement and run machine
learning workloads on Azure; in particular, using Azure Machine Learning Service. This entails planning and creating a suitable
working environment for data science workloads on Azure, running data experiments and training predictive models,
managing and optimizing models, and deploying machine learning models into production.
Skills measured
- The content of this exam will be updated on May 22, 2020. Please download the skills measured document below to see what will be changing.
- Set up an Azure Machine Learning workspace (30-35%)
- Run experiments and train models (25-30%)
- Optimize and manage models (20-25%)
- Deploy and consume models (20-25%)
Latest effective Microsoft DP-100 exam practice questions
QUESTION 1
You plan to preprocess text from CSV files. You load the Azure Machine Learning Studio default stop words list.
You need to configure the Preprocess Text module to meet the following requirements:
Ensure that multiple related words from a single canonical form.
Remove pipe characters from text.
Remove words to optimize information retrieval.
Which three options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
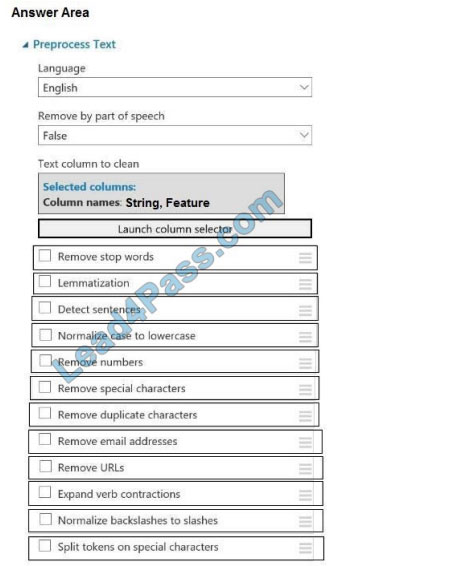
Correct Answer:
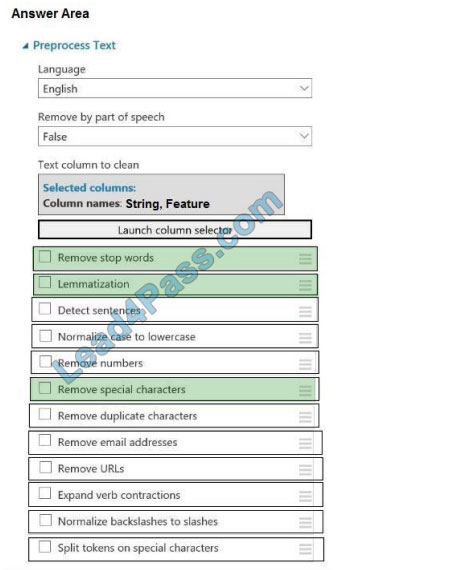
Box 1: Remove stop words
Remove words to optimize information retrieval.
Remove stop words: Select this option if you want to apply a predefined stopword list to the text column. Stop word
removal is performed before any other processes.
Box 2: Lemmatization
Ensure that multiple related words from a single canonical form.
Lemmatization converts multiple related words to a single canonical form
Box 3: Remove special characters
Remove special characters: Use this option to replace any non-alphanumeric special characters with the pipe |
character.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/preprocess-text
QUESTION 2
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
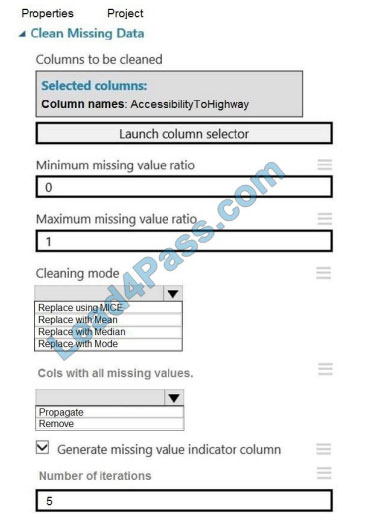
Correct Answer:

Box 1: Replace using MICE
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method
described in the statistical literature as “Multivariate Imputation using Chained Equations” or “Multiple Imputation by
Chained Equations”. With a multiple imputation method, each variable with missing data is modeled conditionally using
the other variables in the data before filling in the missing values.
Scenario: The AccessibilityToHighway column in both datasets contains missing values. The missing data must be
replaced with new data so that it is modeled conditionally using the other variables in the data before filling in the
missing
values.
Box 2: Propagate
Cols with all missing values indicate if columns of all missing values should be preserved in the output.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than tin- other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Principal Components Analysis (PCA) sampling mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
QUESTION 4
You are performing clustering by using the K-means algorithm.
You need to define the possible termination conditions.
Which three conditions can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Centroids do not change between iterations.
B. The residual sum of squares (RSS) rises above a threshold.
C. The residual sum of squares (RSS) falls below a threshold.
D. A fixed number of iterations is executed.
E. The sum of distances between centroids reaches a maximum.
Correct Answer: ACD
AD: The algorithm terminates when the centroids stabilize or when a specified number of iterations are completed.
C: A measure of how well the centroids represent the members of their clusters is the residual sum of squares or RSS,
the squared distance of each vector from its centroid summed overall vectors. RSS is the objective function and our
goal is to minimize it.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/k-means-clustering
https://nlp.stanford.edu/IR-book/html/htmledition/k-means-1.html
QUESTION 5
You need to implement a feature engineering strategy for the crowd sentiment local models. What should you do?
A. Apply analysis of variance (ANOVA).
B. Apply a Pearson correlation coefficient.
C. Apply a Spearman correlation coefficient.
D. Apply a linear discriminant analysis.
Correct Answer: D
The linear discriminant analysis method works only on continuous variables, not categorical or ordinal variables.
Linear discriminant analysis is similar to an analysis of variance (ANOVA) in that it works by comparing the means of the
variables.
Scenario:
Data scientists must build notebooks in a local environment using automatic feature engineering and model building in
machine-learning pipelines.
Experiments for local crowd sentiment models must combine local penalty detection data.
All shared features for local models are continuous variables.
Incorrect Answers:
B: The Pearson correlation coefficient, sometimes called Pearson\\’s R test, is a statistical value that measures the linear relationship between two variables. By examining the coefficient values, you can infer something about the
strength of the relationship between the two variables, and whether they are positively correlated or negatively
correlated.
C: Spearman\\’s correlation coefficient is designed for use with non-parametric and non-normally distributed data.
Spearman\\’s coefficient is a nonparametric measure of statistical dependence between two variables and is sometimes
denoted by the Greek letter rho. The Spearman\\’s coefficient expresses the degree to which two variables are
monotonically related. It is also called Spearman rank correlation because it can be used with ordinal variables.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/fisher-linear-discriminant-analysis
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation
Testlet 2
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to
complete each case. However, there may be additional case studies and sections on this exam. You must manage your
time to
ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case
study. Case studies might contain exhibits and other resources that provide more information about the scenario that is
described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make
changes before you move to the next section of the exam. After you begin a new section, you cannot return to this
section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the
content of the case study before you answer the questions. Clicking these buttons displays information such as
business
requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the
information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a
QUESTION 6
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
SMOTE is used to increase the number of underrepresented cases in a dataset used for machine learning. SMOTE is a
better way of increasing the number of rare cases than simply duplicating existing cases.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
QUESTION 7
You are retrieving data from a large data store by using Azure Machine Learning Studio.
You must create a subset of the data for testing purposes using a random sampling seed based on the system clock.
You add the Partition and Sample module to your experiment.
You need to select the properties for the module.
Which values should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: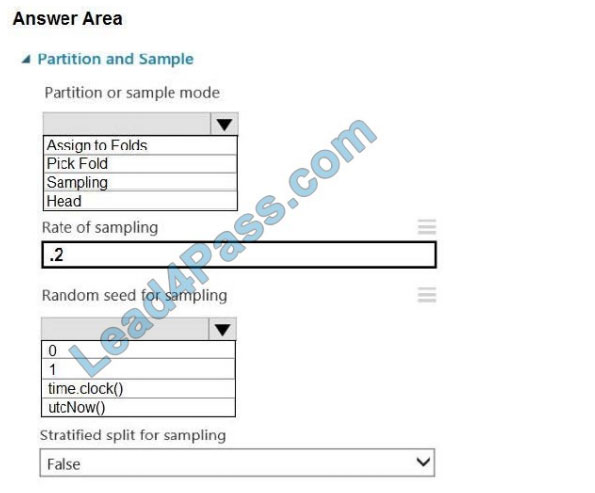
Correct Answer:
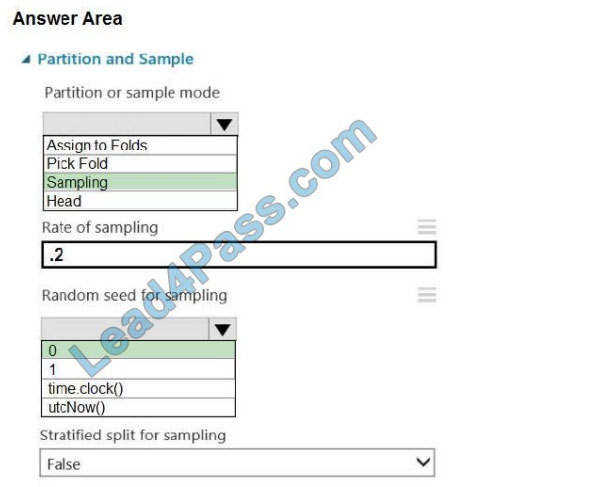
Box 1: Sampling Create a sample of data This option supports simple random sampling or stratified random sampling.
This is useful if you want to create a smaller representative sample dataset for testing.
1.
Add the Partition and Sample module to your experiment in Studio, and connect the dataset.
2.
Partition or sample mode: Set this to Sampling.
3.
Rate of sampling. See box 2 below.
Box 2: 0
3. Rate of sampling. Random seed for sampling: Optionally, type an integer to use as a seed value.
This option is important if you want the rows to be divided the same way every time. The default value is 0, meaning that
a starting seed is generated based on the system clock. This can lead to slightly different results each time you run the
experiment.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
QUESTION 8
You are developing a linear regression model in Azure Machine Learning Studio. You run an experiment to compare
different algorithms. The following image displays the results dataset output: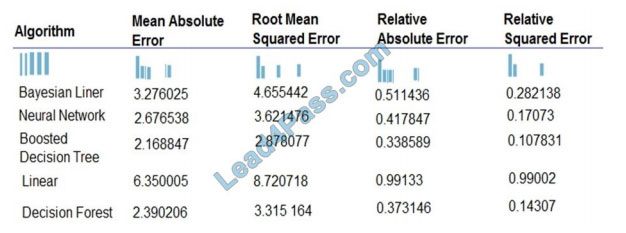
Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the image. NOTE: Each correct selection is worth one point.
Hot Area:
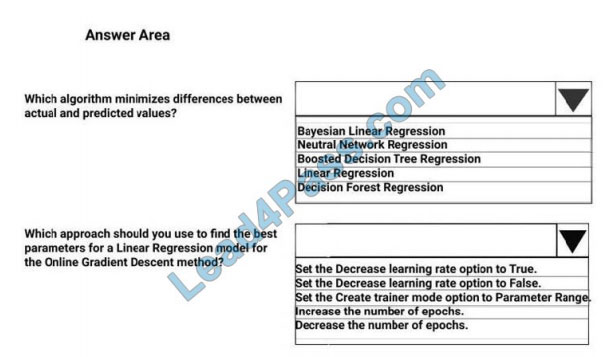
Correct Answer:

Box 1: Boosted Decision Tree Regression
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is
better.
Box 2:
Online Gradient Descent: If you want the algorithm to find the best parameters for you, set Create trainer mode option to
Parameter Range. You can then specify multiple values for the algorithm to try.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
QUESTION 9
You are performing feature scaling by using the sci-kit-learn Python library for x.1 x2, and x3 features. Original and
scaled data is shown in the following image.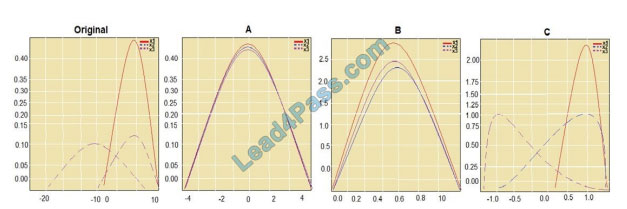
Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
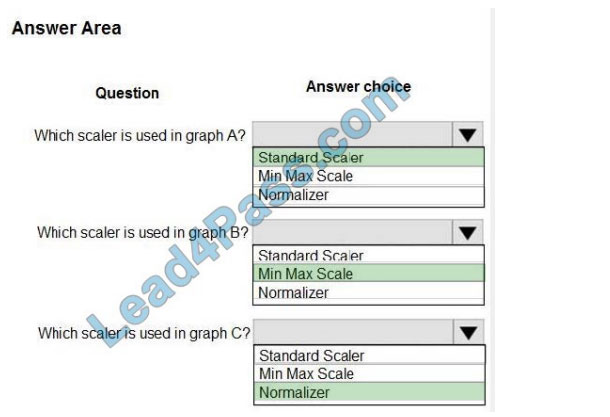
Box 1: StandardScaler
The StandardScaler assumes your data is normally distributed within each feature and will scale them such that the
distribution is now centered around 0, with a standard deviation of 1.
Example:
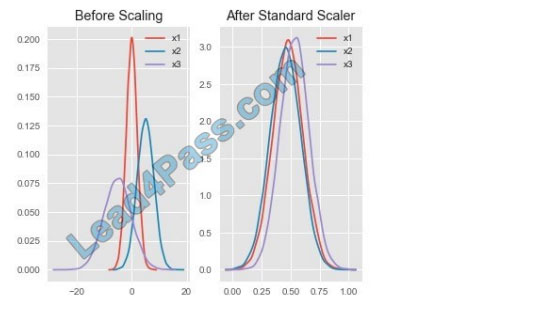
All features are now on the same scale relative to one another. Box 2: Min Max Scaler
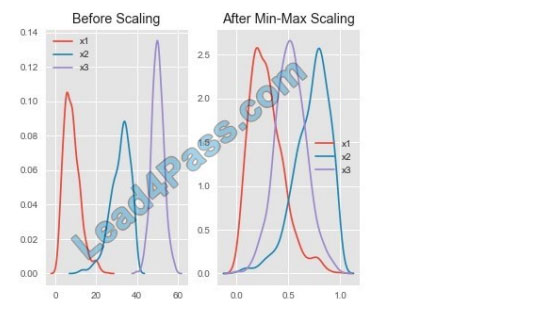
Notice that the skewness of the distribution is maintained but the 3 distributions are brought into the same scale so that
they overlap.
Box 3: Normalizer
References:
http://benalexkeen.com/feature-scaling-with-scikit-learn/
QUESTION 10
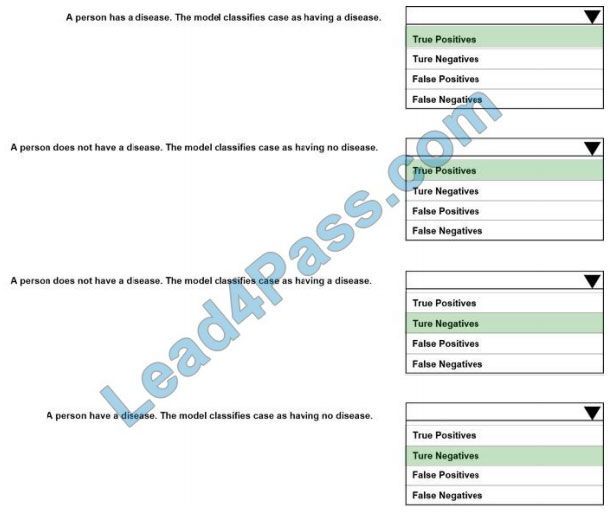
HOTSPOT
You create a binary classification model to predict whether a person has a disease. You need to detect possible
classification errors.
Which error type should you choose for each description? To answer, select the appropriate options in the answer
area;
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
QUESTION 11
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place: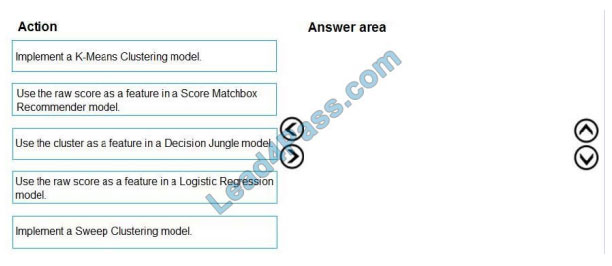
Correct Answer:
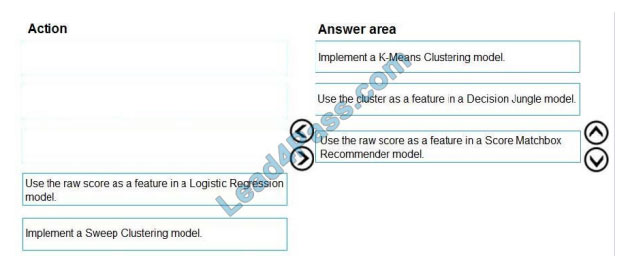
Step 1: Implement a K-Means Clustering model
Step 2: Use the cluster as a feature in a Decision jungle model.
Decision jungles are non-parametric models, which can represent non-linear decision boundaries.
Step 3: Use the raw score as a feature in a Score Matchbox Recommender model
The goal of creating a recommendation system is to recommend one or more “items” to “users” of the system.
Examples of an item could be a movie, restaurant, book, or song. A user could be a person, group of persons or other
entity with
item preferences.
Scenario:
Ad response rated declined.
Ad response models must be trained at the beginning of each event and applied during the sporting event.
Market segmentation models must optimize for similar ad response history.
Ad response models must support non-linear boundaries of features.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/multiclass-decision-jungle
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/score-matchbox-recommender
QUESTION 12
You are performing a filter-based feature selection for a dataset 10 build a multi-class classifies by using Azure Machine
Learning Studio.
The dataset contains categorical features that are highly correlated to the output label column.
You need to select the appropriate feature scoring statistical method to identify the key predictors.
Which method should you use?
A. Chi-squared
B. Spearman correlation
C. Kendall correlation
D. Person correlation
Correct Answer: A
QUESTION 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are creating a model to predict the price of a student\\’s artwork depending on the following variables: the
student\\’s length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relative
Squared Error, and the Coefficient of Determination.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
The following metrics are reported for evaluating regression models. When you compare models, they are ranked by the metric you select for evaluation.
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is
better.
Root mean squared error (RMSE) creates a single value that summarizes the error in the model. By squaring the
difference, the metric disregards the difference between over-prediction and under-prediction.
Relative absolute error (RAE) is the relative absolute difference between expected and actual values; relative because
the mean difference is divided by the arithmetic mean.
Relative squared error (RSE) similarly normalizes the total squared error of the predicted values by dividing by the total
squared error of the actual values.
Mean Zero One Error (MZOE) indicates whether the prediction was correct or not. In other words: ZeroOneLoss(x,y) = 1
when x!=y; otherwise 0.
Coefficient of determination often referred to as R2, represents the predictive power of the model as a value between 0
and 1. Zero means the model is random (explains nothing); 1 means there is a perfect fit. However, caution should be
used in interpreting R2 values, as low values can be entirely normal and high values can be suspect.
AUC.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
Share lead4Pass Microsoft DP-100 Discount codes for free 2020

leads4pass Reviews
leads4pass offers the latest exam exercise questions for free! Microsoft exam questions are updated throughout the year.
leads4pass has many professional exam experts! Guaranteed valid passing of the exam! The highest pass rate, the highest cost-effective!
Help you pass the exam easily on your first attempt.
What you need to know:
Pursue4pass shares the latest Microsoft DP-100 exam dumps, DP-100 pdf, DP-100 exam exercise questions for free. You can improve your skills and exam experience online to get complete exam questions and answers guaranteed to pass the exam we recommend leads4pass DP-100 exam dumps
Latest update leads4pass DP-100 exam dumps: https://www.leads4pass.com/dp-100.html (125 Q&As)
[Q1-Q13 PDF] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1ivuMI2KAwmZmsPjmEiO0TXsfU77hI1Km
![[2017 New] Latest Cisco 642-263 Dumps Exam Practice Materials Online Free Download](https://www.pursue4pass.com/wp-content/themes/instorm/img/thumb-medium.png)
